

0G's first proprietary AI model is live, and it trained on its own network
0GM-1.0-35B-A3B is open source under Apache 2.0, runs in the 0G Private Computer today, and was trained on 0G Compute. The full circle is closed.
Drafted in part with 0GM-1.0.
Earlier this week we wrote: "Your stake is your subscription. Lock $0G. Unlock prompts. Infinite AI."
That was the tease. This is the receipt.
0GM-1.0-35B-A3B is now live: the first AI model 0G trained, deployed, and serves through its own stack. Open source under Apache 2.0. Available right now at pc.0g.ai/models/0GM-1.0-35B-A3B. Trained on 0G Compute, the decentralized GPU network that already runs as one of the four 0G layers.
This is the moment 0G stops hosting AI and starts shipping it.
What's launching
0GM-1.0-35B-A3B is a Mixture of Experts model fine-tuned in-house by 0G for agentic coding, tool use, and long-context reasoning. The base is Qwen 3.6 35B-A3B. The fine-tune, the data pipeline, and the deployment are 0G's. The model card is public at HuggingFace.
| Specification | Value |
|---|---|
| Architecture | qwen3_5_moe (Mixture of Experts) |
| Total parameters | 35B |
| Active per token | ~3B (8 routed + 1 shared, of 256 experts) |
| Native context length | 262,144 tokens |
| Extensible context | Up to 1,010,000 tokens |
| Max output | 32,768 tokens |
| Modality | Image-text-to-text, vision encoder included |
| Reasoning | Thinking mode default, <think>...</think> tags |
| Training network | 0G Compute (decentralized GPU) |
| License | Apache 2.0 |
| HuggingFace repo | 0G-AI/0GM-1.0-35B-A3B-0427 |
The MoE design is the practical point. Of the 35B total parameters, only ~3B activate per token through a router that picks 8 of 256 experts plus 1 shared expert. The headline parameter count reads like a frontier model. The runtime cost reads like a small dense model. That tradeoff is the whole bet.
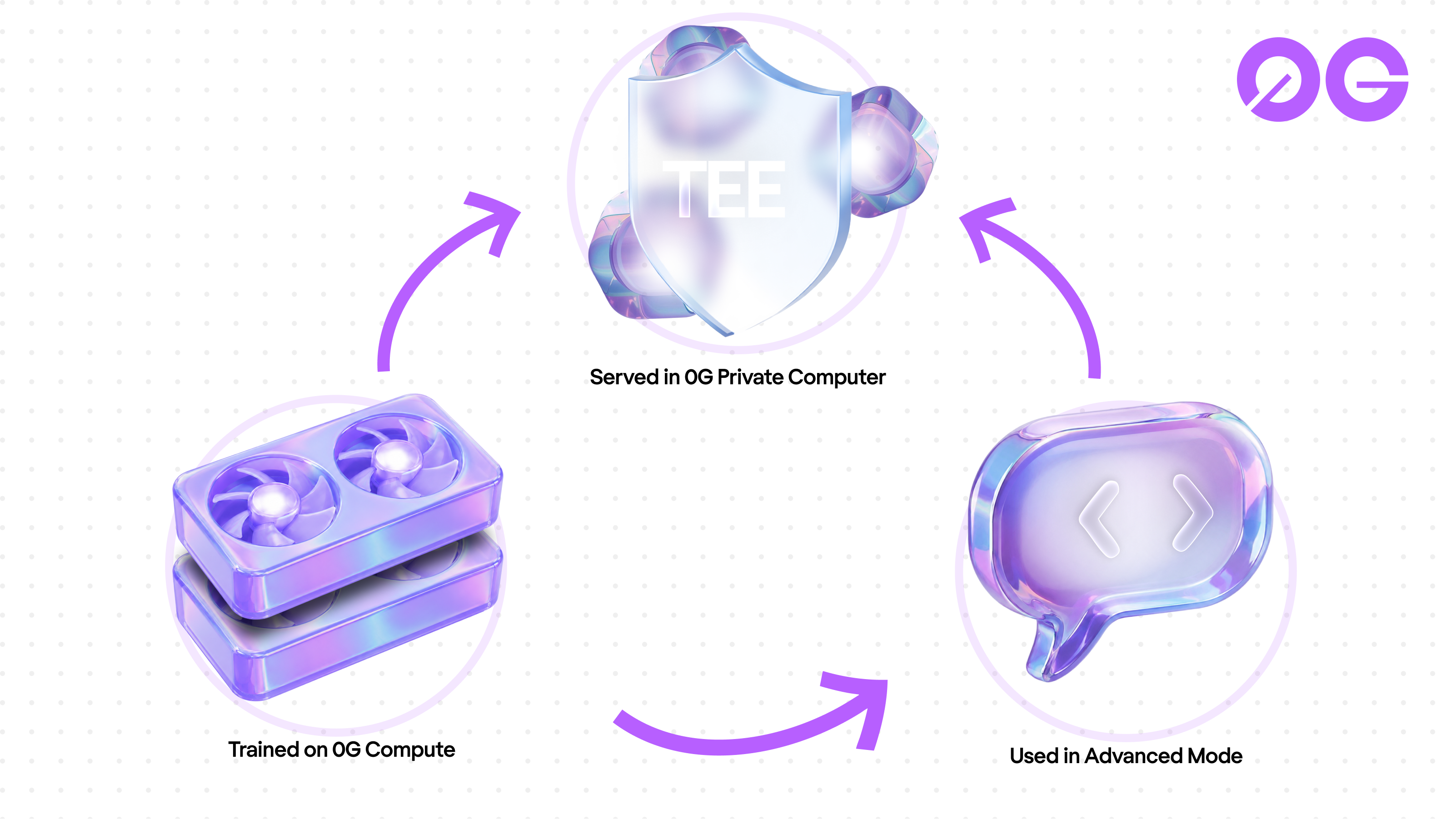
What "sovereign" actually means here
Most "Web3 AI" models are not Web3 models. They are frontier models from a few US labs, rented through API gateways, wrapped in token economics. The chain settles payment. The intelligence layer does not live on the chain.
0GM-1.0 is different in three concrete places:
- It trained on 0G's own network. Not OpenAI compute, not AWS, not a private datacenter that happens to accept crypto. The pre-training and post-training runs happened on 0G Compute, the same decentralized GPU marketplace that hosts third-party AI workloads today.
- It was fine-tuned in-house. The recipe, the dataset mix, the hyperparameters, and the eval are 0G's. The result ships under Apache 2.0. Anyone can audit, run, or fork the weights.
- It runs on 0G's Private Computer. Sealed Inference inside a TEE. Hardware proves what happened inside the box. Nobody in the inference pipeline can see the prompt or the response.
That closes a loop nobody else in this space has closed end to end. Trained here. Served here. Paid for here. The intelligence layer is now sovereign infrastructure, not a thin wallet wrapped around someone else's API key.
Built for agentic coding
The fine-tune is specific: agentic coding and tool use, with reasoning kept on by default. Three things follow.
Tool calling is first class. The model is post-trained on multi-step tool chains, not single-shot completions. Hand it a three-tool schema and it composes them. Hand it a function spec plus a codebase to edit and it plans the diff before writing.
Reasoning is the default mode. Every answer comes wrapped in <think>...</think> tags before the final response. For coding tasks that means the model writes the spec out loud, catches its own mistakes, then writes the code. The model card recommends temperature=0.6, top_p=0.95 for coding workloads, tight enough to stay on task and loose enough to explore tradeoffs.
And the context window matters. 262,144 tokens native, extensible to 1,010,000. The cache token price is $0.05 per million. A 200K-token codebase reload costs roughly one cent. Reasoning over a full repository becomes a default workflow, not a special case.
The base is Qwen 3.6 35B-A3B. The fine-tune was run on 0G Compute. The training story and the runtime story are the same story.
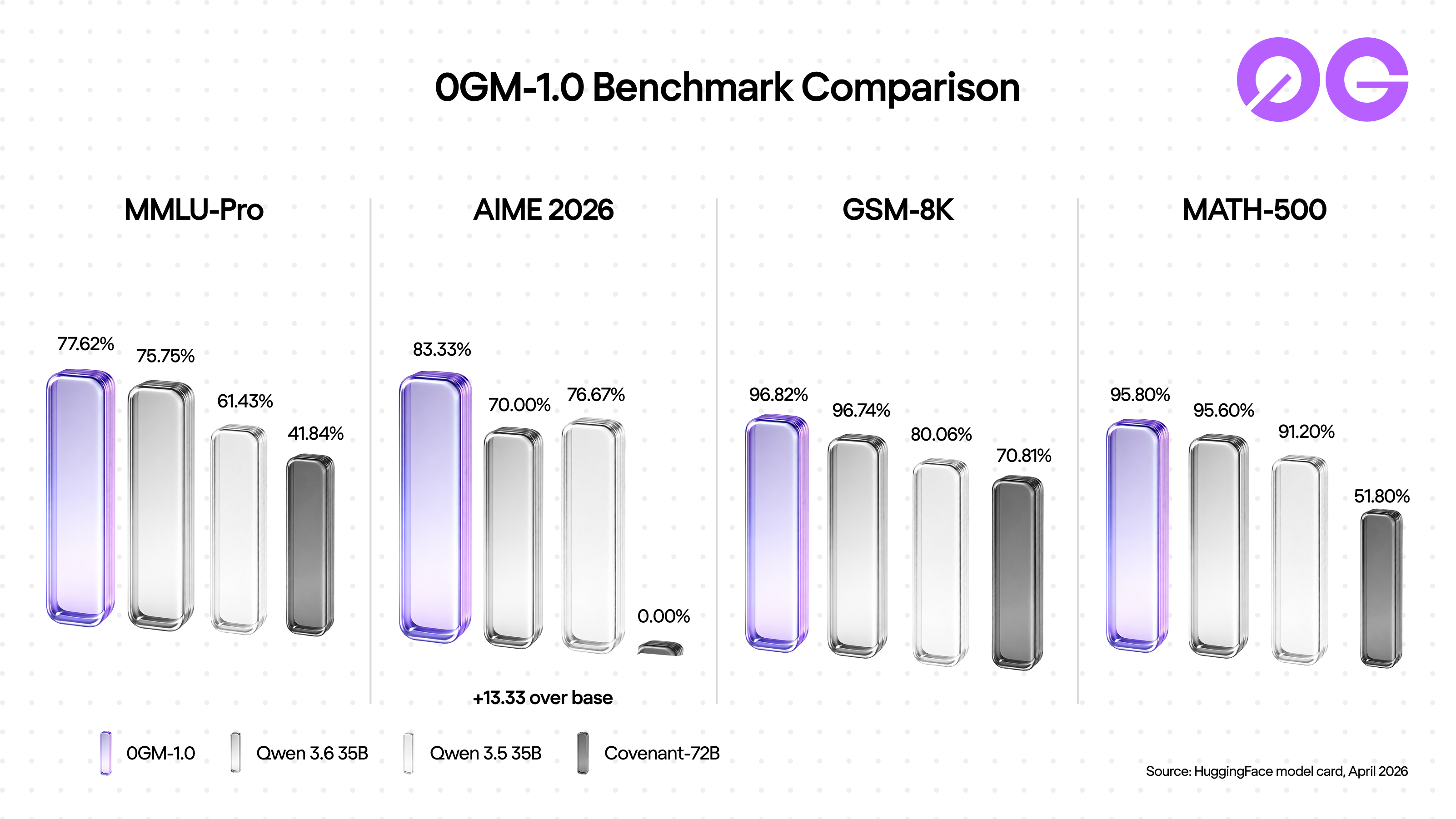
How it stacks up
The HuggingFace model card publishes four benchmark suites. Across all four, 0GM-1.0 ranks at or above its Qwen 3.6 base:
| Benchmark | 0GM-1.0-35B-A3B | Qwen 3.6 35B (base) | Qwen 3.5 35B | Covenant-72B |
|---|---|---|---|---|
| MMLU-Pro | 77.62% | 75.75% | 61.43% | 41.84% |
| AIME 2026 | 83.33% | 70.00% | 76.67% | 0.00% |
| GSM-8K | 96.82% | 96.74% | 80.06% | 70.81% |
| MATH-500 | 95.80% | 95.60% | 91.20% | 51.80% |
Source: HuggingFace model card, April 2026.
The headline gain is AIME 2026, the competition math benchmark: +13.33 points over Qwen 3.6. The fine-tune kept the base's math fluency and added stronger competition-style problem solving on top. On MMLU-Pro the biggest subject jumps are physics (+5.1), philosophy (+4.8), engineering (+4.4), and computer science (+2.5). The shape of the gain is reasoning-heavy domains.
This is a preview revision (0427). The next release will publish a wider eval suite including coding-specific benchmarks (HumanEval, SWE-bench, MBPP). Watch the HuggingFace card for that update.
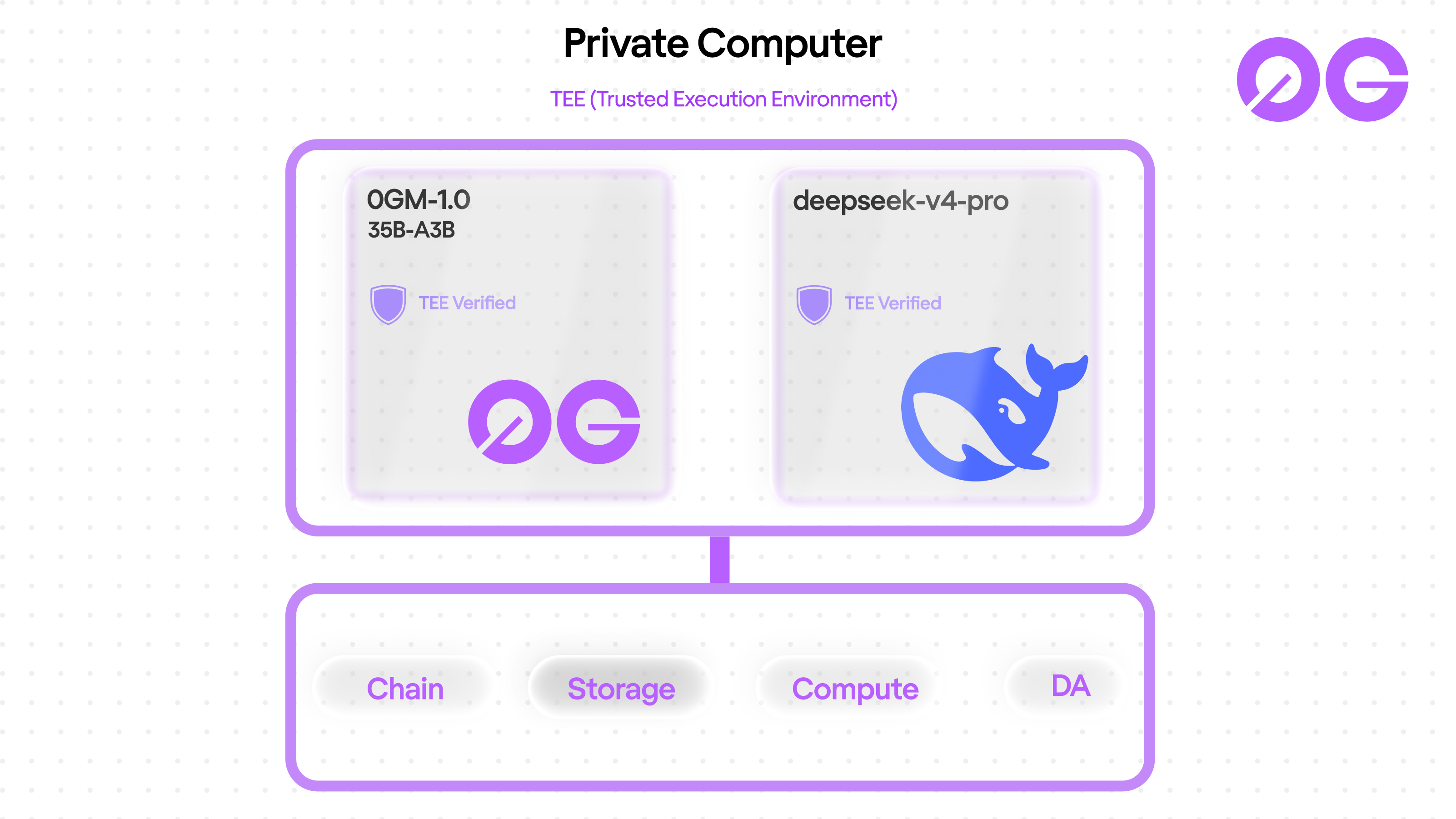
The Private Computer stack today
0GM-1.0 ships alongside a second model in the same Private Computer update: deepseek-v4-pro, a frontier model served via Alibaba Bailian over teetls. Both sit inside Sealed Inference. Both bill per token in $0G with hourly-adjusted FX rates.
The split is intentional. 0GM-1.0 is the sovereign tier: lower cost, owned by 0G, trained on 0G, fine-tuned for agentic coding. deepseek-v4-pro is the frontier tier: state-of-the-art capability for the hardest generalist workloads, served with the same TEE guarantees. Builders pick by job.
| Tier | Model | Input / Output (per 1M) | Cache | Best for |
|---|---|---|---|---|
| Sovereign | 0GM-1.0-35B-A3B | $0.16 / $0.96 | $0.05 | Agentic coding, tool use, long context |
| Frontier | deepseek-v4-pro | $2.10 / $4.20 | n/a | Hardest reasoning, generalist breadth |
That makes the full stack visible: 0G Chain for settlement, 0G Storage for data, 0G Compute for training and inference, and now 0G's own model on top. As of this week it is the only stack in production where every layer is owned by the same protocol.
Try it on pc.0g.ai
Three kinds of work fit cleanly into 0GM-1.0 today. None of these need a developer account or setup beyond a wallet connection.
Routine writing. Ask it to draft a follow-up email to your landlord about a faucet that still leaks a week after you mentioned it in person. You get four sentences that chain cause to effect (drip, then water pooling, then "schedule a plumber"), include practical access logistics ("so I can make sure I'm home"), and close warmly. The reasoning trace below the response shows the model planning the email sentence by sentence before writing.
Code generation from spec. Hand it a signature like scrape_links(url) with constraints (error handling for ConnectionError and HTTPError, return a list of strings, under 25 lines). It writes idiomatic Python: separate except branches by error type, BS4's native find_all('a', href=True) filter to skip dead anchors at parse time, type-prefixed error messages, semantic loop variable names. Constraints respected, no docstring fluff added.
Agentic tool chain planning. Give it three tools (search_web, fetch_url, summarize) and a research question. It returns a plan with editorial reasoning per step ("we assume the first result contains the core definition"), names intermediate state semantically (retrieved_page_text), and respects the "stop after planning" instruction so it does not pretend to execute the tools.
The same model handles all three. Sealed Inference applies to every prompt by default, and the "Verify" button next to each response opens the TEE attestation from the provider's secure enclave. The reasoning trace inside each answer shows exactly how the model decomposed the prompt before writing: restate the request, name the subtasks, then execute. That internal loop is the agentic coding fine-tune showing up in every kind of work, not just code.
What this means for builders
Three things are usable today.
- The weights are open source. Apache 2.0, on HuggingFace, downloadable now. Build on them, fine-tune them further, or run them on your own hardware. No API gate, no Terms-of-Service tightening, no model deprecation schedule outside your control. SGLang is the recommended production runtime. vLLM and Apple's MLX work for local experimentation. Quantize the weights to 4 bits (a single
mlx_lm.convertstep) and the model fits in roughly 18 GB on disk. That puts local inference within reach on a 32 GB+ Apple Silicon Mac or a desktop with a 24 GB consumer GPU, so personal-hardware inference is a real option for builders who want the model off cloud entirely. - The hosted version is already live.
pc.0g.aiAdvanced Mode → select 0GM-1.0-35B-A3B. Sealed Inference inside the TEE. Pay-per-prompt in $0G. Same hardware-attested guarantees that the frontier tier gets. - Router Mode integrates 0GM-1.0 by default. No need to pick the model manually. The router sends agentic coding, tool use, and long-context workloads to 0GM-1.0 and falls back to deepseek-v4-pro for general reasoning. One endpoint, two tiers behind it.
- Call it from your code through an OpenAI-compatible API. Provider endpoints follow the OpenAI API format via a
/v1/proxysurface. Create anapp-sk-<SECRET>key from the Dashboard, point your OpenAI SDK at the provider's service URL, and the samechat.completions.createcalls you already write work against 0GM-1.0:
from openai import OpenAI
client = OpenAI(
base_url='<service.url>/v1/proxy',
api_key='app-sk-<SECRET>'
)
completion = client.chat.completions.create(
model='0GM-1.0-35B-A3B',
messages=[
{'role': 'user', 'content': 'Hello!'}
]
)
print(completion.choices[0].message)cURL and JavaScript drop-ins live at pc.0g.ai/sdk/api-reference/0GM-1.0-35B-A3B. The TEE attestation is still automatic on every call: no extra headers, no client-side verification step, every response carries provider proof you can check on chain.
If you are building an agentic coding tool, an in-IDE assistant, or any system that wants both open weights AND verifiable inference, this is the first weight set on the market that gives you both at once.
Frequently asked questions
Is 0GM-1.0 fully open source?
Yes. Apache 2.0 license. Weights, model card, and tokenizer are public at HuggingFace. It runs locally on any inference framework that supports Qwen 3 MoE checkpoints. SGLang is recommended for production. vLLM, llama.cpp, and Apple MLX work for smaller-scale local use.
Why a Mixture of Experts model?
MoE separates "model capacity" (how much it knows) from "runtime cost" (how much it spends per token). 35B total parameters give it a wide knowledge base. Only ~3B activate per token, so inference is roughly as fast as a small dense model. For agentic coding workloads with high call volume, throughput matters more than peak quality per call.
What does "trained on 0G Compute" mean exactly?
The pre-training and post-training runs happened on 0G Compute, the decentralized GPU marketplace inside the 0G stack. The same network that already serves public AI workloads, used here directly by 0G for our own model.
Can I use this for non-coding work?
Yes. The fine-tune specializes in agentic coding and tool use, but the base reasoning carries across. MMLU-Pro and AIME scores show strong general performance. Inside the Private Computer, Router Mode may still route non-coding workloads to deepseek-v4-pro by default for generalist breadth. You can override the routing in Advanced Mode.
How does pricing work in $0G?
Rate cards are USD-denominated and hourly FX-pegged. Input tokens at $0.16 per million, output at $0.96 per million, cache at $0.05 per million. Settlement happens on 0G Chain in $0G. The FX rate updates hourly so the USD cost per prompt stays stable.
Can it process images too?
Yes. The model is image-text-to-text capable; the vision encoder ships in the open weights and the production deployment now supports image input on the same OpenAI-compatible endpoint.
Can I turn off the reasoning trace?
Yes. Pass chat_template_kwargs={'enable_thinking': False} in your request to suppress the structured thinking output. Useful for production agent stacks where you want clean responses without the trace.
Build on 0G
- Chat with 0GM-1.0 right now: pc.0g.ai/models/0GM-1.0-35B-A3B
- Pull the weights: HuggingFace
- Build with the 0G stack: 0G Documentation
- Follow @0G_labs for the rest of the Infinite AI rollout
Sources:
- HuggingFace: 0G-AI/0GM-1.0-35B-A3B-0427 (model card, benchmarks, specs)
- pc.0g.ai (live deployment, Advanced Mode)
- Infinite AI tease, May 11 2026 (narrative anchor)



