

GLM-5.2 is live on 0G
The frontier of open models just moved. GLM-5.2, the new flagship from Z.ai (Zhipu AI), is the highest-ranked open-weight model on the Artificial Analysis Intelligence Index. Every model scoring above it is proprietary, from Anthropic and OpenAI. For the first time the top open-weight slot belongs to a model anyone can download, inspect, and run.
The catch is how you reach it. The usual path to a frontier model is a centralized endpoint, where you send your prompt and trust, on policy alone, that it goes where the provider says. For a person in a dashboard that gap is fine. For an autonomous agent working on proprietary code or user data, trust-by-policy is the weak link.
GLM-5.2 is now live on 0G, and there are two doors. Builders query it at pc.0g.ai/models/glm-5.2, routed through a TeeTLS-attested transport layer to Alibaba Bailian, where the model runs. Every routing hop is provable onchain. Everyone else can open 0G Private Chat at app.0g.ai/private-chat, pick GLM-5.2 from the model selector with no API key, and chat with it privately. Both doors went live the same day Z.ai open-sourced the model. GLM-5.2 powers the intelligence. 0G makes the access verifiable.
The GLM family has been on 0G since GLM-5 first arrived. GLM-5.2 is the newest, and it joins the verifiable-frontier tier next to DeepSeek V4 Pro and Qwen 3.7 Max.
What's launching
GLM-5.2 is reachable today on both surfaces of the 0G Private Computer. For builders, the API surface is the 0G Router at https://router-api.0g.ai/v1, a single public endpoint in the OpenAI format that normalizes requests and responses across every model on the platform. For everyone else, 0G Private Chat is a no-key chat app with a model selector.
| Specification | Value |
|---|---|
| Model | GLM-5.2 (glm-5.2) |
| Developer | Z.ai (Zhipu AI) |
| Positioning | "Frontier Intelligence, Open Weights," built for long-horizon tasks |
| Parameters | 744B total / 40B active (Z.ai reports; HuggingFace auto-count reads 753B) |
| Context window | 1M tokens (verified live on 0G) |
| Max output | 131,072 tokens |
| Modality | Text in, text out |
| Reasoning | reasoning_effort max (default) or high; extended thinking on by default |
| Tool use | Native function calling, OpenAI tools schema (verified live) |
| License | MIT open weights |
| Hosted inference | Alibaba Bailian |
| 0G verification | TeeTLS-attested routing |
| Endpoint | https://router-api.0g.ai/v1 (OpenAI-compatible) |
GLM-5.2 uses the same app-sk-* key flow that already serves 0GM-1.0, DeepSeek V4 Pro, Qwen 3.7 Max, and the rest of the lineup. It joins as a separate, newer deployment.
The top open-weight model
Z.ai built GLM-5.2 for long-horizon work: autonomous task decomposition, architecture design, full-stack development, integration testing, and multi-platform deployment. Extended thinking runs by default, so every response carries a reasoning trace, and the API exposes two effort levels, max for the hardest problems and high for a tighter balance of quality and token spend. The context window is 1M tokens, which is now a floor across the frontier rather than the story.
On the Artificial Analysis Intelligence Index, GLM-5.2 scores 50.7, the highest-ranked open-weight model on the index, with every model above it proprietary (Artificial Analysis, June 17, 2026). That is a jump of more than ten points over GLM-5.1 on the same index version. Z.ai reports task-level coding results of 81.0 on Terminal-Bench 2.1 and 62.1 on SWE-bench Pro, both well ahead of GLM-5.1; on Terminal-Bench 2.1 that is within a few points of Claude Opus 4.8. It is the top open-weight model, not the top model overall, and the chart below keeps that honest.

How 0G serves GLM-5.2: TeeTLS-attested routing
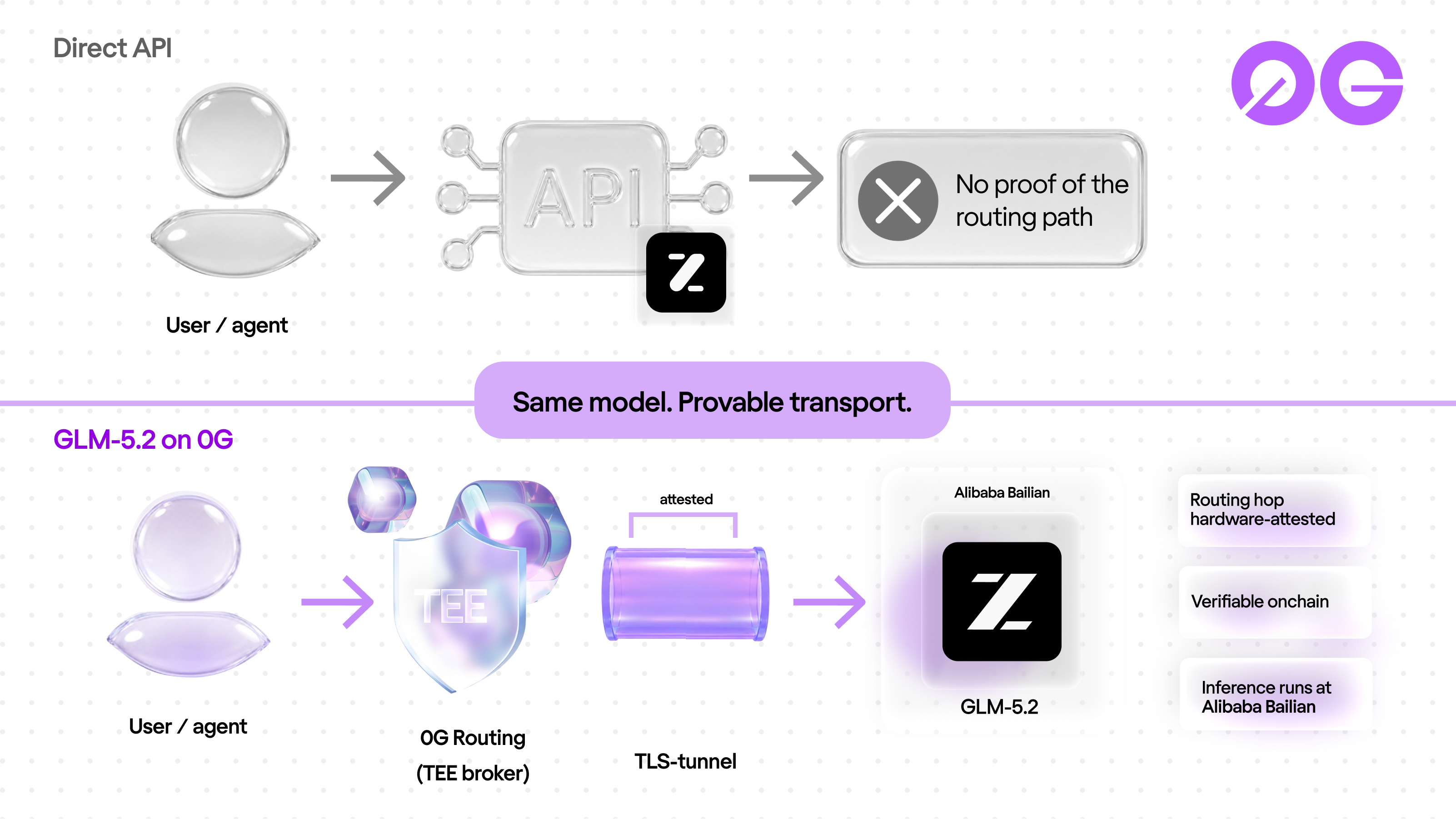
GLM-5.2 is MIT open-weight, so it could in principle be self-hosted. For this launch, 0G serves it through TeeTLS-attested routing: the inference runs on Alibaba Bailian, and 0G adds a verifiable routing layer on top. 0G does not host, run, or seal GLM-5.2's inference, and the deployment never pretends otherwise.
The 0G Private Computer exposes two trust models on one key flow. TeeML is the sovereign tier: the model runs inside a TEE-sealed enclave that 0G operates, and the operator cannot read the prompt. 0GM-1.0 uses this. TeeTLS is the verifiable-frontier tier: a broker runs inside a TEE and proxies your request to a centralized provider over HTTPS. The TLS handshake to the upstream runs inside that enclave, so the routing path is provable: you can check which upstream received the prompt and that the transport was not intercepted or silently redirected. The inference happens at the upstream. GLM-5.2 uses TeeTLS; the upstream is Alibaba Bailian.
That is a smaller-scope guarantee than full enclave inference, and it is the honest one for a launch-scale frontier model. 0G does not claim to run GLM-5.2's inference. It attests the path your prompt takes to Bailian, and proves onchain which upstream received it and how the transport was protected. Every provider on the 0G Compute Network is verified by the 0G team before it is listed.
What 0G adds over a direct API
A direct call to a centralized model API gives you the model and nothing else. You cannot prove where the prompt went, what protected it in transit, or that it reached the endpoint you intended. For a human in a dashboard that gap is usually acceptable. For an autonomous agent that runs unattended and handles proprietary code, user data, or value, the gap bites: acting on a redirected or intercepted prompt, it has no way to know.
The 0G deployment closes that gap without changing the model. You still talk to GLM-5.2. The difference is that the routing is hardware-attested and recorded onchain, so an agent, or whoever audits it later, can verify the transport rather than assume it. That is what "the Blockchain for AI Agents" means in practice: the intelligence stays with the model maker, and the trust layer becomes something you can check. Send verify_tee: true in the request body and the response trace returns x_0g_trace.tee_verified: true, which you can check against the provider's onchain attestation.
Chat with it privately, the same day
Not everyone reaching for GLM-5.2 wants to write code. 0G Private Chat at app.0g.ai/private-chat is the no-key door: open it, pick GLM-5.2 from the model selector, and start chatting. There is no account friction and no SDK.
Private Chat shows how each model is secured. Every model carries a verifiability badge, so GLM-5.2 displays its TeeTLS badge right next to the conversation, the same trust guarantee builders get through the API. As new models land on 0G Compute, they come into Private Chat the same day. GLM-5.2 open-sourced and became privately chattable on 0G in the same 24 hours.
Build with it
Existing OpenAI-compatible client code runs against the 0G deployment with one base URL change.
from openai import OpenAI
client = OpenAI(base_url="https://router-api.0g.ai/v1", api_key="app-sk-<YOUR_KEY>")
response = client.chat.completions.create(
model="glm-5.2",
messages=[{"role": "user", "content": "Decompose this codebase migration into ordered steps."}],
)
print(response.choices[0].message.content)
Native function calling works end-to-end: send an OpenAI tools=[...] payload and the response returns a proper tool_calls array. Extended thinking is on by default, so responses include a reasoning trace alongside the answer; pass reasoning_effort: "high" when you want a tighter token budget than the max default. For onchain TEE attestation in the trace, set verify_tee: true. Router Mode picks a model for the workload automatically; Advanced Mode lets you target glm-5.2 directly.
Pricing in $0G
Usage is USD-denominated and settled on 0G Chain. GLM-5.2 is $0.97 per million input tokens and $3.39 per million output, settled in $0G (about 3.23 / 11.31 $0G per million at the June 17 2026 FX peg, which floats hourly). That tracks the broader market for reaching the model through API providers; the deployment exists for the verifiable, private routing on top, not for a price advantage. For workloads that legally cannot send prompts to a centralized endpoint without proof of the routing path, that is the reason it is here.
Frequently asked questions
Does 0G host or run GLM-5.2's inference?
No. Alibaba Bailian hosts and runs the model. 0G's contribution is a TeeTLS-attested routing layer that proves onchain which upstream your prompt was sent to and how the transport was protected. The model stays with its host; the verifiable routing is 0G's.
How is querying GLM-5.2 on 0G different from a centralized API?
A direct API gives you the model with no proof of where your prompt went. The 0G deployment routes through a broker inside a TEE to Alibaba Bailian and records the routing onchain, so an agent or an auditor can verify the transport instead of trusting it by policy. Same model, provable path.
Can I use GLM-5.2 without writing code?
Yes. Open 0G Private Chat at app.0g.ai/private-chat, pick GLM-5.2 from the model selector, and chat with it privately. No API key, no SDK. The TeeTLS verifiability badge shows next to the conversation.
Is GLM-5.2 open-weight?
Yes. GLM-5.2 ships under the MIT license, with weights on HuggingFace. On 0G it is served through TeeTLS-attested routing to a launch-scale host rather than self-hosted, which is why the trust model is verifiable routing rather than enclave-sealed inference.
What is 0G?
0G is the Blockchain for AI Agents, a decentralized infrastructure stack for chain, storage, data availability, and compute. The 0G Private Computer is where AI models become queryable onchain with verifiable trust guarantees.
Where can I get 0G?
get.0g.ai is the interactive guide on how and where to acquire 0G tokens, with options for developers, investors, and ecosystem participants.
Where can I build on 0G?
Start with the 0G documentation, then query GLM-5.2 directly at pc.0g.ai.
Build on 0G
- Query GLM-5.2 now: pc.0g.ai/models/glm-5.2
- Chat with it privately, no key: app.0g.ai/private-chat
- Pull the open weights: HuggingFace
- Read the trust-model details: docs.0g.ai
- See the verifiable-frontier companions: DeepSeek V4 Pro and Qwen 3.7 Max
- Follow @0G_labs for what goes live next on 0G private compute
Sources:
- GLM-5.2 launch and benchmarks (Z.ai, model positioning and coding results)
- GLM-5.2 on HuggingFace (MIT license, architecture, open weights)
- Artificial Analysis Intelligence Index, GLM-5.2 (Intelligence Index 50.7, highest open-weight, June 17, 2026)
- 0G Compute Network inference docs (TeeML and TeeTLS definitions, app-sk key flow)
- DeepSeek V4 Pro is live on 0G and Qwen 3.7 Max is live on 0G (verifiable-frontier tier companions)
- GLM-5 is live on 0G (the GLM family on 0G)



