

GLM-5 on 0G Compute: 744B open-source AI, zero data logging
Every time you use a cloud AI service, your prompts pass through someone else's servers. Your code and your data, handled by infrastructure you don't control. For most use cases, that's fine. But for teams building with sensitive data, regulated industries, or proprietary code, it's a problem that no API terms of service can truly solve.
GLM-5, the highest-ranked open-source AI model available today, just went live on 0G Compute. And on this infrastructure, nobody, not even the hardware operator, can see your prompts.
What GLM-5 brings to the table
GLM-5 is a 744 billion parameter mixture-of-experts model built by Zhipu AI, released under the MIT license in February 2026. Only 40 billion parameters activate per token, which keeps inference fast while giving the model access to a massive knowledge base.
It ranks #1 among all open-source models on the Artificial Analysis Intelligence Index, and #6 overall. Every model above it is proprietary. Here's the full picture, with frontier proprietary and open-source models side by side:
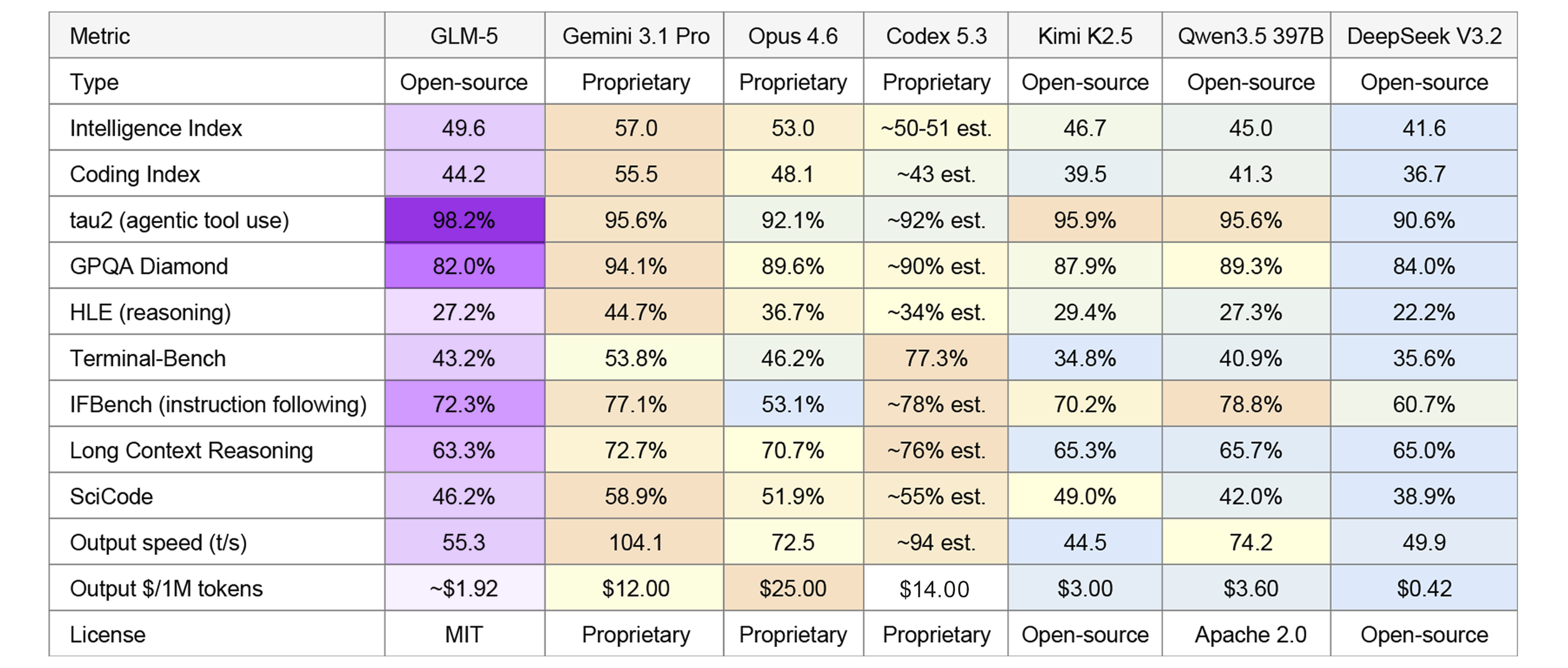
GLM-5 output price on 0G Compute at current 0G token rate (~$0.60/0G). Codex 5.3 pricing from OpenRouter. All other data from Artificial Analysis, February 2026.
GLM-5 leads every model on tau2-Bench, the benchmark for agentic tool use: calling APIs, reading data, chaining actions. That's the kind of work coding assistants and automation pipelines do all day.
Where it trades off: scientific reasoning (GPQA, HLE) and raw speed, where Gemini 3.1 Pro leads. Codex 5.3 dominates Terminal-Bench, well ahead of everything else.
GLM-5 is also the industry leader in knowledge reliability, with the best hallucination score on the AA-Omniscience Index across all models, open and closed.
But look at the bottom rows. GLM-5 on 0G Compute costs a fraction of every proprietary model at comparable quality, and it ships under MIT, so you can fine-tune it, deploy it commercially, or modify the weights.
The privacy problem with centralized AI
In February 2026, an investigation by Swedish newspapers Göteborgs-Posten and Svenska Dagbladet revealed that contractors in Kenya reviewing Meta Ray-Ban smart glasses footage were seeing people undressing, reading bank cards, and watching medical visits. Over 7 million units sold in 2025 according to EssilorLuxottica's earnings report, and the privacy protection is a terms-of-service document that doesn't even cover the bystanders being filmed. Privacy policies fail. They get buried, updated quarterly, and ignored by the systems they govern.
The same pattern plays out in AI infrastructure. Every time you send a prompt to a cloud AI provider, you're trusting that company with your data. For many use cases, that trust is fine. For others, it's a dealbreaker.
Consider what happens when a development team uses an AI coding assistant. Every code snippet and architecture discussion flows through a third party's servers. The provider's terms of service govern what happens to that data, and those terms can change with a quarterly update.
Regulated industries face this even more sharply. Healthcare teams can't send patient data to a general-purpose API, and financial institutions have compliance frameworks that flat-out prohibit sending certain data to external services.
Open-source models solved half of this problem. You can download GLM-5's weights from HuggingFace today and run them on your own hardware. But "your own hardware" usually means renting GPU time from AWS, GCP, or Azure, which brings you right back to a centralized provider who controls the infrastructure. (For more on why 0G should be part of your stack, see our earlier breakdown.)
The question has always been: where do you run a frontier open-source model with genuine privacy guarantees, not just a promise in a terms of service?
How 0G Compute changes the equation
0G Compute is a decentralized GPU marketplace where providers offer computing power and users pay only for what they consume. No monthly minimums, no vendor lock-in.
GPU providers on 0G Compute can run workloads inside Trusted Execution Environments (TEEs), hardware-isolated enclaves where even the machine operator cannot access the data being processed. Your prompts enter the enclave, get processed, and the results come back. The provider never sees the raw input.
Providers on the network do not retain user data after processing. This isn't a terms-of-service promise that might change next quarter.
On the verification side, 0G supports TEEML, OPML, and ZKML. Each method provides cryptographic evidence that the computation ran correctly on the model you requested. Payments settle through on-chain smart contract escrow: funds lock when you submit a request and release when computation is verified. No intermediary can freeze your account or deny service.
The result: you get the same GLM-5 model, the same 744B parameters, the same benchmark performance, but running on infrastructure where no single entity controls your data.
Six models are currently live on 0G Compute mainnet:
| Model | Type | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|---|
| GLM-5 | Chatbot | 1 0G (~$0.60) | 3.2 0G (~$1.92) |
| DeepSeek Chat v3 | Chatbot | 0.30 0G (~$0.18) | 1.00 0G (~$0.60) |
| gpt-oss-120b | Chatbot | 0.10 0G (~$0.06) | 0.49 0G (~$0.29) |
| Qwen3-VL 30B | Chatbot | 0.49 0G (~$0.29) | 0.49 0G (~$0.29) |
| Whisper Large v3 | Speech-to-Text | 0.05 0G (~$0.03) | 0.11 0G (~$0.07) |
| z-image | Text-to-Image | - | 0.003 0G (~$0.002)/image |
USD estimates at current 0G token rate of ~$0.60. Actual cost depends on 0G market price at time of use.
What it costs
GLM-5 is available through multiple inference providers. Here's how they compare on pricing and privacy:
| Provider | Input $/1M | Output $/1M | Privacy |
|---|---|---|---|
| 0G Compute | ~$0.60 (1 0G) | ~$1.92 (3.2 0G) | TEE + decentralized |
| AtlasCloud | $0.95 | $3.15 | No |
| Z.ai (direct API) | $1.00 | $3.20 | No |
| Together AI | $1.00 | $3.20 | No |
| Fireworks | $1.00 | $3.20 | No |
| Phala Network | $1.20 | $3.50 | TEE (decentralized) |
0G Compute price at current 0G token rate of ~$0.60. Z.ai is GLM-5's creator (Zhipu AI). Additional providers (Parasail, Friendli, GMICloud, Venice, Novita) offer GLM-5 at $1.00/$3.20. Sources: OpenRouter GLM-5, Artificial Analysis, Z.ai Pricing.
On output pricing, 0G Compute is the cheapest option that also provides privacy guarantees. Phala Network also offers TEE-based privacy but at a higher price point. Only on 0G Compute do your prompts stay inside a hardware-isolated enclave at the lowest output cost in the market.

Get started in 5 minutes
0G Compute exposes an OpenAI-compatible API. If you've used the OpenAI SDK before, you already know how this works.
Step 1: Get your API key
Go to the 0G Compute Marketplace and connect your wallet (MetaMask or any EVM-compatible wallet on 0G Mainnet).
- Fund your account. Go to the Wallet page and deposit at least 5 0G tokens. This creates your main ledger account and covers initial usage.
- Pick a model. Go to Inference, find zai-org/GLM-5-FP8, and click Build.
- Transfer funds to the provider. In the Setup panel, transfer at least 5 0G to the GLM-5 provider for stable service.
- Generate an API key. Click Generate New Key. You'll get a key starting with
app-sk-. Copy it and keep it safe.
That's it. You now have a base URL and an API key:
Base URL: https://compute-network-1.integratenetwork.work/v1/proxy
API Key: app-sk-Step 2: Send your first request
cURL
curl https://compute-network-1.integratenetwork.work/v1/proxy/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer app-sk-" \
-d '{
"model": "zai-org/GLM-5-FP8",
"messages": [
{"role": "user", "content": "Explain quantum computing in two sentences."}
],
"max_tokens": 4096
}' Python (OpenAI SDK)
from openai import OpenAI
client = OpenAI(
base_url='https://compute-network-1.integratenetwork.work/v1/proxy',
api_key='app-sk-'
)
response = client.chat.completions.create(
model='zai-org/GLM-5-FP8',
messages=[{'role': 'user', 'content': 'Hello!'}],
max_tokens=4096
)
print(response.choices[0].message.content)JavaScript (OpenAI SDK)
import OpenAI from 'openai';
const client = new OpenAI({
baseURL: 'https://compute-network-1.integratenetwork.work/v1/proxy',
apiKey: 'app-sk-'
});
const response = await client.chat.completions.create({
model: 'zai-org/GLM-5-FP8',
messages: [{ role: 'user', content: 'Hello!' }],
max_tokens: 4096
});
console.log(response.choices[0].message.content);Note: GLM-5 reasons before answering, and max_tokens covers both thinking and output. For quick tests, 4096 (the default) works. For coding tasks or AI assistants like Claude Code, use 16384 or higher. For complex multi-step reasoning, you can go up to 65536. If you set it too low, the model spends its entire token budget on thinking and returns an empty answer.
Step 3: Run Claude Code on 0G
Claude Code proxy. Run Claude Code with GLM-5 as the inference backend:
ANTHROPIC_BASE_URL="https://compute-network-1.integratenetwork.work/v1/proxy" \
ANTHROPIC_AUTH_TOKEN="app-sk-" \
claude --model "zai-org/GLM-5-FP8" All three variables are inline, no config files needed. Claude Code will use GLM-5 for that session.
MCP server for coding assistants. If you use Claude Code, Cursor, or Windsurf, the 0G Code to Coin MCP server routes your AI requests through 0G Compute directly from your IDE:
npm install @0gfoundation/0g-cc
claude mcp add 0g-cc npx @0gfoundation/0g-cc -e ZEROG_NETWORK=mainnetAgent skills. The 0G Agent Skills repository provides 14 ready-made skills for Claude Code, Cursor, and GitHub Copilot:
git clone https://github.com/0gfoundation/0g-agent-skills .0g-skillsFor full SDK documentation, see 0G Compute SDK docs.

Frequently asked questions
How does GLM-5 compare to frontier proprietary models? GLM-5 (49.6 Intelligence Index) is the highest-ranked open-source model, just below Claude Opus 4.6 (53.0) and Gemini 3.1 Pro (57.0). It leads all models on agentic tool use (98.2% tau2-Bench). Codex 5.3 leads Terminal-Bench (77.3%). GLM-5 output on 0G Compute runs ~$1.92/1M tokens vs $14-25 for frontier proprietary models. Source: Artificial Analysis, OpenRouter.
Is my data really private on 0G Compute? Yes. TEE verification means your prompts are processed inside hardware-isolated enclaves that even the GPU operator cannot access. Providers on the network do not retain user data after processing. Verifiable computation proofs confirm the model ran correctly without exposing your inputs.
What other models are available on 0G Compute? Six models are live on mainnet: GLM-5, DeepSeek Chat v3, gpt-oss-120b, Qwen3-VL 30B, Whisper Large v3 (speech-to-text), and z-image (text-to-image). New models are added as providers bring them online.
How do I get 0G tokens for compute? 0G tokens are available on supported exchanges. Visit CoinMarketCap or CoinGecko for the latest information on acquiring tokens. Testnet tokens are available for free for development and testing.
Start building
GLM-5 on 0G Compute is live today. The SDK documentation covers everything from first request to production deployment. The 0G Agent Skills repo gets your AI coding assistant up to speed in minutes.
If you're building AI applications where privacy actually matters, where your users' data isn't someone else's training set, this is the stack to evaluate.
Sources
- Svenska Dagbladet: Meta's AI smart glasses and data privacy concerns
- CNBC: Ray-Ban maker EssilorLuxottica triples Meta AI glasses sales in 2025
- Artificial Analysis: GLM-5 Intelligence, Performance & Price Analysis
- 0G Compute Network Documentation
- 0G Agent Skills Repository
- @0gfoundation/0g-cc MCP Server
- Z.ai Official Pricing
- OpenRouter GLM-5 Pricing
- Ming Wu (@spark_ren), 0G CTO, February 19, 2026
- 0G Labs (@0G_labs), February 19, 2026



