

0G Private Computer: Verifiable AI Inference
Multiple models, one OpenAI-compatible API, every request sealed inside a TEE. Live today at pc.0g.ai.
Most AI APIs are a trust exercise. You send a prompt, the provider says it does not look at it, your request runs in a black box, the response comes back, and you take their word for everything that happened in between.
That model held while AI was a nice-to-have. It does not hold when an agent is signing transactions, managing keys, or deciding what to do with your data.
0G Private Computer is the alternative. It is live today at pc.0g.ai. Multiple models, four categories of inference, one OpenAI-compatible API, and every request runs inside a Trusted Execution Environment so the operator can prove what happened without seeing what was inside.
This post is the long-form walk-through: what shipped, how it works, and why we built it the way we did.
What 0G Private Computer is
0G Private Computer is a decentralized AI inference platform that gives builders chat, vision, speech, and image generation through a single endpoint. It is the same product surface that frontier AI companies expose, with one big difference under the hood: the compute runs inside hardware-isolated chip enclaves on a decentralized network, paid for in 0G, with cryptographic proof that the model and your inputs were not tampered with.
If you have written code against the OpenAI Python or JavaScript SDK, you already know how to use it. The integration is one line: swap the base URL.
from openai import OpenAI
client = OpenAI(
base_url="https://router-api.0g.ai/v1",
api_key="",
)
response = client.chat.completions.create(
model="",
messages=[{"role": "user", "content": "Hello!"}],
stream=True,
) That is the full migration. No new SDK to learn. No new mental model. The agent harness or backend service you wrote against OpenAI keeps working, only now it terminates against a network of verified providers instead of one company.

The OpenAI-compatible flip
The decision to ship an OpenAI-compatible router was deliberate. It removes the single largest objection to using decentralized AI: the cost of switching.
Decentralized infrastructure has a habit of inventing its own SDKs, its own job submission flow, its own settlement primitives. That keeps integrators away. Builders pick the path that does not require a rewrite.
So 0G Private Computer points at the path everyone is already on. The router endpoint at router-api.0g.ai/v1 mirrors the OpenAI HTTP surface. The routing layer underneath handles provider discovery, balance management, and onchain settlement so the developer never has to think about it.
The result is that an agent built last week against OpenAI can be moved to a network where every inference is verifiable, and the only code change is in the constructor. Same chat completions, same streaming, same tool-calling shape, different trust model.
For teams that want lower-level control, Advanced mode (pc.0g.ai/sdk) exposes the underlying SDK directly. The mental model is simple: Router is one address (router-api.0g.ai/v1) that picks a provider for each request, draws from a single balance, and handles the onchain payment in the background. Advanced gives you provider-specific endpoints, per-provider sub-accounts, and direct ledger access if you want to control which provider runs your traffic. Same network either way. Router is the default; Advanced is one click in the top right when you need that level of control.
What "verifiable" means here
The verifiability story is the part that takes a paragraph to land.
Every inference request on 0G Private Computer runs inside a Trusted Execution Environment. The provider hardware combines an Intel TDX-enabled CPU and a NVIDIA H100 or H200 GPU with TEE support. Together they form an enclave that the host operating system cannot see into. The model loads inside the enclave, the prompt enters the enclave encrypted, the output is signed inside the enclave before it leaves, and the host machine sees only encrypted traffic in and out.
This matters because policy-based privacy ("we do not look at your data") and architectural privacy ("the machine operator physically cannot look at your data") are different products. The first is a promise. The second is a hardware guarantee with a cryptographic signature attached.
For an agent that holds a wallet, that signs onchain transactions, that has read access to private API keys, the difference is the difference between "we hope nobody peeks" and "no one in the supply chain physically can." When AI models start moving money, the second is the only one that scales.
The TEE-verified badge appears on every model card and on the response. That badge is not branding. It is the readable surface of an attestation that ties the response back to the specific enclave that produced it.
Models in the launch lineup
Four categories live today: chat, vision, speech, and image generation. Six models on Router, seven with Advanced mode, all running inside TEE-verified enclaves. The pattern in the lineup is that each model is one a builder would already reach for in its category, only now sitting behind the same OpenAI-compatible endpoint.
- Deepseek chat-v3-0324: open-source coding and reasoning at frontier scale. Mixture-of-Experts model with 685B parameters, so inference stays affordable while keeping the breadth of a frontier-class model.
- Qwen3.6 Plus: Alibaba's flagship language model with a 1M-token context window. Long enough for whole codebases, large RAG corpora, or full document sets in a single pass. Live on 0G after the Alibaba Cloud x Qwen integration shipped on April 16.
- GLM-5-FP8: reasoning model with thinking mode on by default. FP8 quantization keeps it fast. Tool-calling works out of the box, and the API shape is OpenAI- and Anthropic-compatible, so migration paths from either ecosystem are short.
- Qwen3-VL-30B: multimodal vision-language. Pass text and images, get text back. Useful for screenshot-to-code, document understanding, and visual reasoning at 30B parameter scale. Served via Alibaba Cloud Model Studio (DashScope, Singapore region), live confirmation of the April 16 Alibaba Cloud x Qwen integration.
- Whisper-large-v3: OpenAI's speech-to-text model. Multilingual transcription and translation. The default choice for production audio pipelines.
- z-image: text-to-image generation. Async, returns base64. Priced at 0.003 0G per image, which scales to volume use cases without rewriting the bill.
Advanced mode (pc.0g.ai/sdk) also lists models that go through a specific provider's endpoint instead of through Router. OpenAI's gpt-5.4-mini is one of them, made verifiable through the Primus zktls attestation flow, so even closed-source providers carry the same TEE proof. Router is the default for most builders; Advanced is one click away when you want a model that has not been pulled into the Router lineup yet, or when you need to pin requests to a specific provider.
Each model card carries the TEE-verified badge. Each request, regardless of category or mode, terminates inside an enclave. That gives builders a single trust model across modalities, instead of having to evaluate every new provider individually.
The lineup will grow. New models get added through the provider broker and become available through the router as they pass verification. Builders do not have to change anything to access them; the router exposes whatever the network is hosting.

The 60-second key flow
The onboarding that ships with Private Computer is shorter than most centralized AI platforms.
Open pc.0g.ai/dashboard/api-keys. Connect a wallet, name a key, click create, copy it. That is the flow. No KYC, no minimum deposit gate, no waiting list. The first request you make against the API works.
One funded wallet supports multiple API keys, so a team can issue per-agent keys without re-funding for each one.
Funding happens in the background. The Router model auto-draws from the balance on the unified account. The dashboard shows usage. When the balance runs out, the user goes to Manage Funds and tops up. There is no separate ledger to manage per provider, no manual sub-account dance, no contract addresses to copy. Settled in 0G token. Fiat support coming soon.
For teams used to the OpenAI signup ("get a key, stack credit, go"), this is the same speed, with the verifiability story behind it.
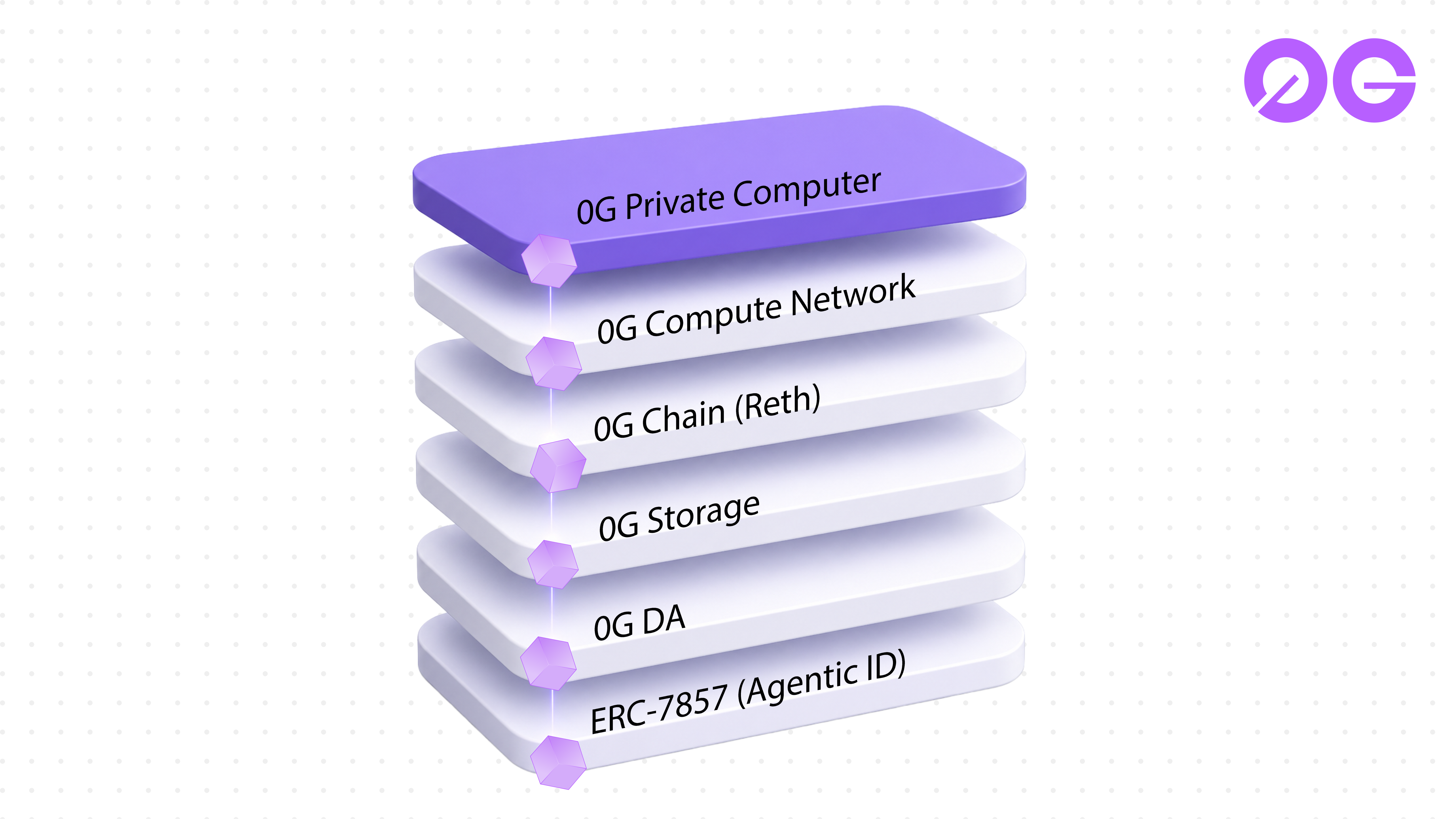
Where Private Computer fits in the 0G stack
0G Private Computer is the inference surface. It sits on top of a stack that has been shipping in pieces for the last six months:
- 0G Chain: an EVM-compatible Layer 1 optimized for AI workloads, migrated from Geth to Reth in March 2026 for execution-layer performance.
- 0G Compute Network: the decentralized GPU marketplace that Private Computer routes to. 16,000+ active nodes, 250K+ daily inference requests, 50 TB stored, sub-120ms average latency, 99.9% uptime at the time of this post.
- 0G Storage: distributed storage with up to 2 GB/s throughput, compared against Filecoin and Arweave in March.
- 0G Data Availability: high-throughput sampling for AI workloads, 50K+ TPS, with cryptographic proofs and instant retrieval.
- ERC-7857 (Agentic ID): the live identity standard for autonomous agents on 0G. When ownership of an agent transfers, its memory is re-encrypted inside the same chip-level enclave Private Computer uses for inference.
Private Computer is the part of this stack that gives a developer something they can integrate against this afternoon. Chat, vision, speech, image generation, settled in 0G token, attested by hardware. The other layers run underneath and stay invisible to the API caller.
This is the difference between an inference platform you read about and one you point your code at.
Who this is for
The primary audience is developers building AI agents. Agents are the workload that breaks the centralized inference model fastest. They run continuously. They hold credentials. They sign transactions. They make decisions based on their input window. Every assumption that a chatbot can shrug off, an agent has to defend.
The secondary audience is teams building privacy-sensitive products: legal, healthcare, finance, anywhere that "we do not look at your data" is not a strong enough commitment. For these teams, the TEE attestation is not a nice-to-have. It is the compliance evidence.
The tertiary audience is retail users who want frontier models without the data deal. The Playground at pc.0g.ai/playground gives that audience a chat interface that runs on the same infrastructure as the API.
How a request actually flows
The site frames the lifecycle in four steps. The same flow applies whether you are in Router mode or driving the SDK directly.
- Browse: open the marketplace, compare models, providers, latency, and per-1M token cost. No wallet required.
- Select: pick a model, sign in, deposit funds into the compute ledger.
- Execute: send inference requests through the decentralized network. Pay only for what you use, token by token.
- Verify: every response is cryptographically verified through TEE attestation. Trustless, transparent, provable.
This is the loop that turns "decentralized AI" from a slide into a working integration: prices visible before you commit, payment recorded onchain after, and an attestation receipt for everything in between.
Frequently asked questions
What is 0G Private Computer?
0G Private Computer (pc.0g.ai) is a decentralized AI inference platform. Developers access multiple models for chat, vision, speech, and image generation through an OpenAI-compatible API. Every request runs inside a TEE-verified enclave, settled in 0G token.
How does the OpenAI compatibility work?
The router endpoint at router-api.0g.ai/v1 mirrors the OpenAI HTTP API. Existing OpenAI SDK code works after a one-line change to the base URL. Chat completions, streaming, and tool-calling shapes are preserved.
What is a TEE and why does it matter?
A Trusted Execution Environment is a hardware-isolated region inside a CPU and GPU that the host operating system cannot inspect. The model runs inside, the prompt enters encrypted, and the output is signed before it leaves. This turns "the operator says they do not look" into "the operator hardware-cannot look." For agents holding keys or signing transactions, this is the relevant trust boundary.
Which models are available at launch?
Deepseek chat-v3-0324, Qwen3.6 Plus, GLM-5-FP8, Qwen3-VL-30B, Whisper-large-v3, and z-image. Chat, vision, speech, and image generation all live in one UI, all running inside TEE-verified enclaves.
How long does it take to get an API key?
Open the dashboard at pc.0g.ai/dashboard/api-keys, connect a wallet, name a key, click create. No KYC form, no minimum deposit gate, no waiting list.
Is this the same product as 0G Compute?
0G Compute is the underlying GPU marketplace. 0G Private Computer is the productized surface on top of it: the router, the dashboard, the Playground, the model catalogue, the OpenAI-compatible API. Same network, packaged for developers and end users.
How does this compare to other private inference projects?
Some ship manifestos on testnet. 0G Private Computer ships in production today, on mainnet, with attestation receipts on every request and an OpenAI-compatible endpoint that accepts traffic the same minute you create a key.
Router vs Advanced mode?
Router (pc.0g.ai) is the default surface: one base URL, one balance, automatic provider routing. Advanced (pc.0g.ai/sdk) exposes the underlying SDK with provider-specific endpoints, per-provider sub-accounts, and direct onchain ledger access. Most builders start in Router. Advanced is for teams that need to pin requests to a specific provider, or for models that go through a specific provider's endpoint instead of through Router. OpenAI's gpt-5.4-mini is one such model on Advanced, made verifiable through the Primus zktls attestation flow.
Build on 0G
Get started in under a minute:
- Get a key: pc.0g.ai/dashboard/api-keys
- Try the Playground: pc.0g.ai/playground
- Read the docs: docs.0g.ai
- Follow @0G_labs
0G is the blockchain for AI agents. Private Computer is where they think.
Sources
- 0G Compute Network SDK (technical reference)
- Inference Provider Guide (TEE hardware spec)
- Alibaba Cloud x Qwen integration on 0G (April 16, 2026)
- Geth to Reth validator migration (chain layer context)
- 0G Storage vs Filecoin and Arweave (storage layer context)



