

0G App Is Live: Chat, Build, and Deploy AI from Your Browser
GLM-5 running inside TEE. A prompt-to-app studio. Decentralized storage with root hash recovery. All at app.0g.ai.
Every major AI platform stores your prompts on their servers, trains on your inputs, and charges $20/month for the privilege. You get a chat interface. They get your data.
0G App, live today at app.0g.ai, gives you the same chat experience with a different trust model. AI inference runs inside sealed hardware enclaves. Your conversations sync to decentralized storage where only you hold the key. And it costs a fraction of what centralized alternatives charge.
This is not about replacing the AI tools you already use. It is about getting the same quality with actual ownership. GLM-5 running inside TEE, a vibe coding studio that turns prompts into deployed web apps, and onchain storage where a cryptographic receipt gives you permanent access to your work.
Prompt. Deploy.
0G App is designed as a full-cycle product: build, chat, launch, and store. Studio is live today. Chat and additional launchers are rolling out over the coming days.
Studio is the centerpiece at launch. Describe what you want, pick a template (landing page, dashboard, web app, or wallet tracker built on Vite and React), and the system generates a complete project with live preview. You can also upload a screenshot or mockup and get an app inspired by the design. Everything runs in WebContainers, a browser-native Node.js runtime with no backend servers. When the app is ready, deploy to Vercel in one click.
Chat brings a conversational AI interface powered by GLM-5, with every inference call running inside TEE enclaves. Chat is currently marked as coming soon in the app and is expected to go live within days of launch.
Launcher Hub houses three tracks: App Launcher (active now, same prompt-to-app engine as Studio), Token Launcher (guided token deployment on 0G Chain, in progress), and Claw Launcher (12 panda-themed AI agents backed by OpenClaw and 0G Compute, in progress). The hub is accessible at app.0g.ai/launchers.
Storage syncs your conversations and generated apps to 0G's decentralized storage layer. More on this below.
GLM-5: 744 billion parameters, sealed inside TEE
0G App launches with GLM-5-FP8, a 744-billion parameter mixture-of-experts model with 40 billion parameters active per token. It scores 50 on the Artificial Analysis Intelligence Index (AAII), placing it in the global top 10 and among the leading open-weight models. On the tau2-Bench agentic tool use benchmark, GLM-5 leads all models at 98.2% (Source: Artificial Analysis, 2026).
| Metric | Value | Source |
|---|---|---|
| Parameters | 744B total, 40B active per token (MoE) | GLM-5 model card |
| Intelligence Index (AAII) | 50 (Top 10 overall, leading open-weight) | Artificial Analysis, 2026 |
| tau2-Bench (agentic) | 98.2% (leads all models) | tau2-Bench, 2026 |
| Input token cost | $0.60 / 1M tokens | 0G Compute, April 2026 |
| Output token cost | $1.92 / 1M tokens | 0G Compute, April 2026 |
| TEE hardware | Intel TDX + NVIDIA H100/H200 | 0G Compute docs |
Every inference call on 0G App runs inside hardware TEE enclaves. Sealed inference means the compute provider operating the hardware cannot access your prompts or outputs. The model processes your request inside a secure enclave, and only you receive the result.
The pricing tells its own story. GLM-5 on 0G Compute runs at $0.60/M input and $1.92/M output. The same model on OpenRouter costs more across every provider, and none of them offer TEE verification (Source: OpenRouter GLM-5 pricing, April 2026; GLM-5 on 0G Compute).
| Provider | Input $/1M | Output $/1M | TEE verified |
|---|---|---|---|
| 0G Compute | $0.60 | $1.92 | Yes |
| DeepInfra | $0.80 | $2.56 | No |
| AtlasCloud | $0.95 | $3.15 | No |
| Venice | $1.00 | $3.20 | No |
For context: the minimum to start using 0G App is 3 $0G, which at current prices is under $2. Compare that to $20/month AI subscriptions where you rent access and own nothing.

Onchain storage with root hash recovery
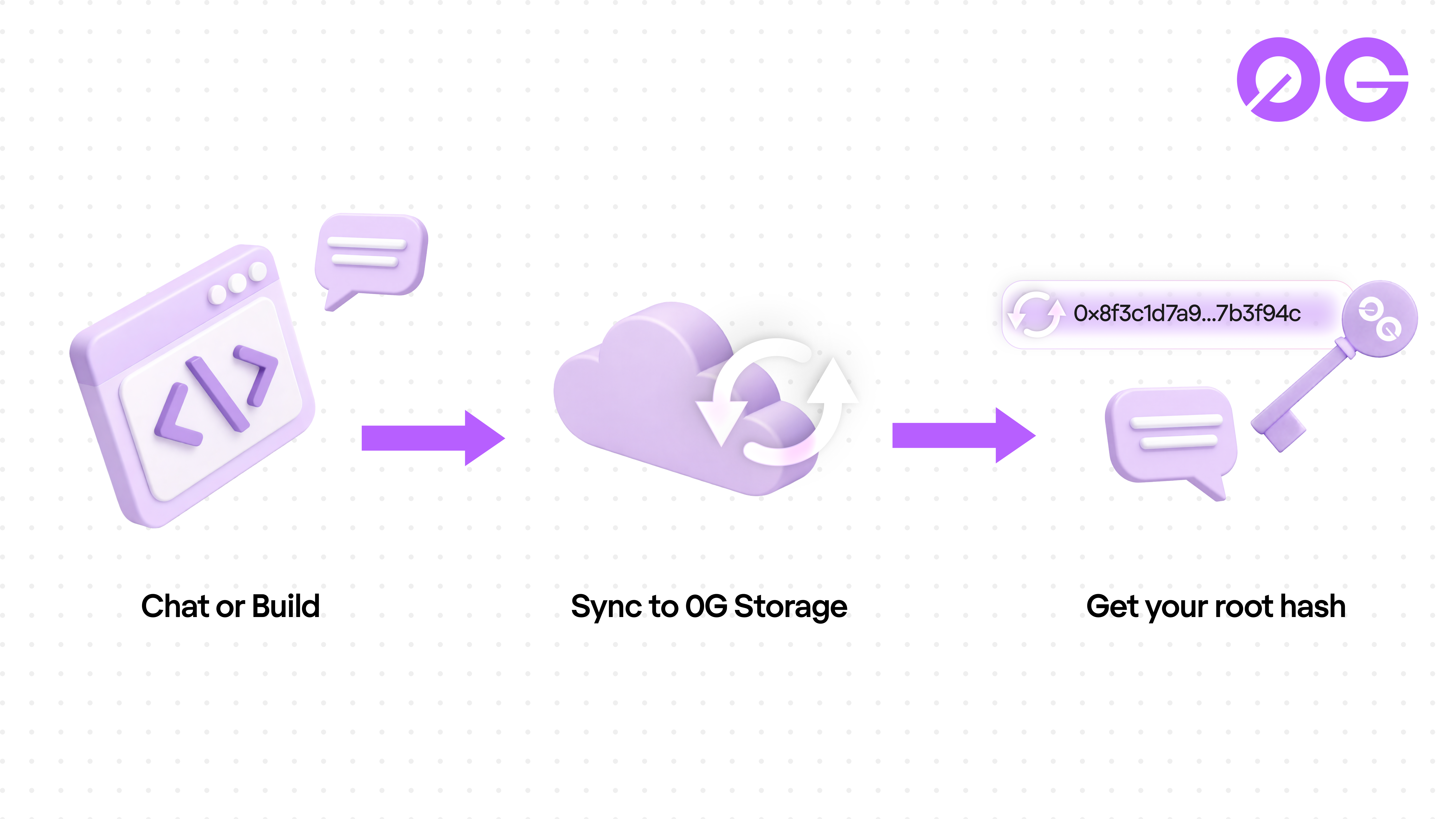
Every conversation and generated app in 0G App syncs to 0G Storage, the decentralized storage layer running at up to 2 GB/s throughput across the network (Source: 0G Storage documentation).
Each sync produces a root hash. Think of it as a cryptographic receipt for your session. Lose your device, clear your browser, switch laptops. Enter the hash and everything restores exactly where you left it: conversation history, app state, all of it.
No account needed to keep your data. No password reset email. No centralized database. Just a hash that only you hold, backed by math instead of a company's promise.
How to get started
Go to app.0g.ai and connect a wallet to start. You need a minimum of 3 $0G to access 0G Compute, which powers all inference on the platform. At current $0G prices, that is under $2 to get started.
Chrome on desktop is the recommended browser. Studio's WebContainer runtime works best there. Email login through Privy is in active development and will be available soon, lowering the barrier to entry for users who do not have a wallet yet.
What ships next
0G App launches with GLM-5. Additional models are coming.
The underlying 0G Compute network already supports multiple TEE-verified models including DeepSeek, Whisper, and image generation. These are available today on 0G Compute for developers using the API directly. The plan is to bring additional models into 0G App progressively, with the goal of adding a new model every week.
Image and video generation capabilities are coming to Studio as well.
0G App sits at the center of a broader product suite. 0G Compute gives developers direct API access to the same model infrastructure. Chat and Studio share the same model backend, so improvements to one benefit both.
With over 300 ecosystem partners, $40M in seed funding, and infrastructure already processing 28M+ blocks, the launch of 0G App adds a consumer-facing entry point to a network that has been building production infrastructure since the Aristotle Mainnet launch in September 2025 (Source: 0g.ai).
Frequently asked questions
What models are available on 0G App?
0G App launches with GLM-5-FP8, a 744B parameter model running inside TEE enclaves. The 0G Compute network already supports additional models (DeepSeek, Whisper, z-image) accessible through the 0G Compute developer API, with plans to bring them into the App progressively. New models are being added weekly.
How much does it cost to use?
You need a minimum of 3 $0G to access 0G Compute, which is under $2 at current prices. GLM-5 inference runs at $0.60/M input tokens and $1.92/M output tokens on 0G. The same model costs $0.80-$1.00/M input on OpenRouter, without TEE verification.
Is my data private?
All inference runs inside TEE enclaves (Intel TDX, NVIDIA H100/H200). The compute provider cannot access your prompts or outputs. Data syncs to 0G's decentralized storage and can be restored using a root hash that only you control.
Can I deploy apps built in Studio?
Yes. Pick from four templates (landing page, dashboard, web app, wallet tracker), describe what you want, and Studio generates a complete project in browser-native WebContainers. Deploy to Vercel in one click. No server setup required.
What browsers work best with 0G App?
Chrome is recommended for the full experience including Studio. Desktop provides the most complete experience at launch.
Build on 0G
Sources:
- 0G App
- GLM-5 on 0G Compute
- Artificial Analysis Intelligence Index
- OpenRouter GLM-5 Pricing
- 0G Documentation
- 0g.ai



